My current client has a service which connects to an old IBM z/OS application (legacy system). The data centre charges for each message sent to this legacy system, rather than using a processor or hardware based pricing model. The output from this legacy system is always the same, since the calculations are idempotent. The application calculates prices for travelling along a given route of the train network. Prices are changed only twice a year through an administration tool. So in order to save money (a hundered thousand dollars a year), the service which connects to this legacy system had an in-memory least-recently-used (LRU) cache built into it, which removes the least recently used entries when it gets full in order to make space for new entries. The cache is quite large, thus avoiding making costly calls to the legacy system. To avoid losing the cache content upon server restarts, a background task was later built to periodically persist the latest data inside this cache. Upon starting a server, the cache content is re-read. Entries within the cache have a TTL (time to live) so that stale entries are discarded and re-fetched from the legacy system.
This cache was great in the beginning because it saved the customer a lot of money, but in the mean time several similar caches have been added, as well as more general caches for avoiding repeated database reads, causing our nodes to need over 1.5 GB of RAM. Analysis has showed that the caches are consuming over 500 MB alone. The platform is WebSphere and IBM only recommends running with 512 MB per node… So as you can see, we are on the road to having some memory issues. In order to avoid these issues, and potentially also save money by requireing less hardware for our applications, I have taken time to think about possible architectures which could solve the problems.
One of the problems is that the cache is an internal part of the service, i.e. it is a glorified Map referenced as a singleton. That means, each node has its own cache instance. Worse actually, because of the class loaders in application servers, each application has its own instance of the service and hence its own instance of the cache, and because the service is deployed per application, each cache exists multiple times per node in the cluster. The result is an architecture as follows, where there are for example 8 instances of the same cache:
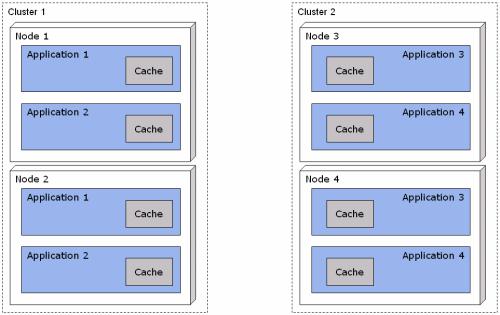
While these in memory caches are quick, that is not the main reason for having created them. The main reasons were to avoid hammering either the database or the legacy systems with repeated queries which result in the same outcome. While the caches theoretically speed up the the applications, the associated increase in garbage collection might actually result in lower overall speed because the garbage collector needs to run more frequently because there is less memory available for use by the application itself, because the caches consume so much.
This got me thinking about creating a centralized cache, of which there is one single instance for use by all applications. The architecture would then look like this:
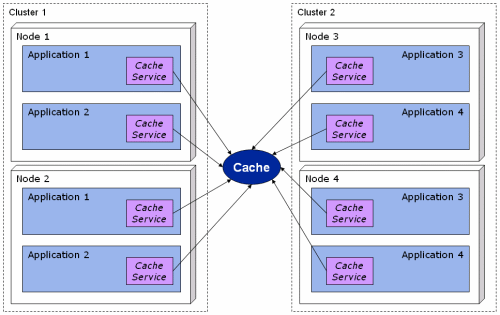
The requirements for the cache are:
- Persistent, so that server restarts do not cause all content to be lost,
- Single, so that the entire landscape contains just one cache rather than the same data being cached lots of times as it is today,
- Relatively fast,
- No impact on existing infrastructure, i.e. if we stick our cache into our database, that influences the reading/writing of other data by making the database perform less well.
So, what are the options for creating such a cache?
- In Memory, but remote, backed by persistence, similar to what we have today, only with the service deployed as a remote EJB, rather than being called locally,
- A bigtable style, NoSQL cache, because they are based on key/value pairs and can handle lots of data,
- LDAP, because LDAP is persistent as well as optimised for read access.
A fourth option might be to use a database cache, i.e. a table devoted to key/value pairs cached in the database, which gets read every time you need data, but this would affect overall database performance, so isn’t really an option. I have however included such a solution in the solutions that I tried below, simply to compare performance.
While the concept of a bigtable style database is aimed at large amounts of data (billions of rows and millions of columns), what is of interest in this case is that it is based on key/value pairs, which is exactly what we need for our cache. The caches used today are LRU caches, because to store all possible data would require too much memory (there are millions of routes on the train network), which is also the reason why we wouldn’t want to store all possible routes in the database. However, because a bigtable style database supports large data sets while maintaining performance, we can potentially just let it contain all possible routes. The strategy for filling such a cache would be to check the cache for the required entry, if it doesn’t exist, to then query the legacy system, and its answer be cached for future use, until it becomes stale.
So first things first, I started up Glassfish for Eclipse and MySQL to do some tests. I created a set of tables to contain 100,000 train stations, generated randomly. Then I added 100,000 random routes, each containing between 3 and twenty stations. It is these routes which the legacy system calculates prices for. The first solution I implemented was a pure database cache, where a query to the service which encapsulates the legacy system first checked if the database contained a cache entry for the key, made up of the "from" station and the "to" station codes. If there was no hit on the cache, the legacy system was queried and its result was cached. I filled the cache with all 100,000 routes and began making measurements. My first results were rather poor, with requiring several hundred milliseconds to read from the cache, even though the cache key was the primary key, that is indexed! OK, the test system was my aging IBM T60 Intel Core Duo (2 core CPU) laptop with only 2 GB RAM, running Windows XP, Glassfish, MySQL, and a handful of other (memory intensive) applications and services.
I started reading up about Cassandra, the Apache application based on bigtable, and in the performance tuning section it mentioned about using two disks for seperate files which it writes. That made me think about what was going on on my laptop and I realised that one reason why my first solution was so slow was that I was running applications using over 2 GB of RAM, so I was well into the region where the OS was using virtual memory and swapping from RAM to disk continuously. Sure enough, during tests, my hard disk light was going crazy. I have been wanting to upgrade this laptop for a while, but it belongs to the client, so I cannot really upgrade it. But I did a little more reading and decided to try out a USB 3.0 external hard disk (500 GB "My Passport" from Western Digital), together with an Expressbus USB 3.0 adapter. This gave me a very fast external hard drive. Random read/write tests showed that this external hard drive was actually up to three times faster than the internal one!
So, I got back to testing, and installed my apps (Glassfish and MySQL, etc) on the external hard drive, leaving the internal harddrive for the OS and disk swapping. In the ideal world, one would do this the other way around and install an SSD for the OS and its swap file, leaving a slower more conventional spinning hard disk for applications and data. Anyway, instead of a single drive having to try to do swapping and reading of say the database simultaneously, this configuration let the internal drive handle swapping, while the external drive handled reading for the database, basically allowing parallel tasks.
Sure enough, I was able to get random cache read times for this database cache, down to 15 milliseconds. It still wasn’t that fast, but interestingly, this database was doing nothing else at all, simply servicing cache reads (i.e. reads out of a single table with a cache key as the primary key, and a varchar for the value (a serialised Java object). Since this solution influences the existing infrastructure, i.e. the database, it would not fulfil the requirements I created earlier in this post.
I next downloaded Cassandra from Apache, and read a few introductions like the ones here and here.
What I wanted to do was not complex at all, so I created a structure with a single ColumnFamily (like a table). I filled it with all 100,000 routes, and started performance testing, and got average read times similar to MySQL. I read up a little more about performance tuning and I discovered that I could control the number of entries cached in memory inside Cassandra. I set this to be 99% and sure enough, my results improved to the point that after a few hundred thousand reads (which would happen fast in production), I was getting read times of around 2 milliseconds. Cassandra was running as a single process on the same laptop on which GlassFish was running, which contained a service which wrapped calls to Cassandra. The data structures were simple with each cache entry stored within a single key in Cassandra, basically having a single column for the ColumnFamily, containing the serialised route object.
Further reading introduced the idea that Cassandra is optimised for reading many columns within a single "row" (key). I tried restructuring the data so that the key for each "row" was the "from" station code, and for each destination from that station, a column was added within the row. So I had many less keys in Cassandra, but many more columns per row. And because these bigtable solutions do not require each key to have identical columns, allowing sparsely filled tables, it was perfect for this restructuring.
I refilled the cache using this new structure, and sure enough, once Cassandra had loaded a few hundred thousand keys and they were all cached in its memory (set at 256 MB for the process), average random read times sank to just 1 millisecond. Compared to MySQL things were looking good.
Time for the next proposed solution, which was to make calls to a remote EJB running in its own node (or rather cluster). I implemented this by creating a simple stateless session EJB which contained a static reference to a Hashtable (so that it was thread safe). I didn’t bother implementing the persistent part in the first instance, because I was interested in how long it would take to simply call the remote EJB and do the lookup in the Map. I deployed the EJB to Apache OpenEJB running as a simple process on the same laptop and after filling the cache completely, the average time for random reads was around 2 milliseconds, i.e. similar to Cassandra, albeit a tiny bit slower.
The final option was to try out LDAP. I only considered this because LDAP is optimised for reading, which is what this service is doing. I used ApacheDS that also as a process on my laptop. I filled LDAP with my 100,000 routes by basically filling my organisation unit with new sub-organisational units per key, with the Base64 encoded serialised object attached to the sub-OU as an attribute, such that the cache entry had a URL like ldap://localhost:10389/ou=8500101_8500103,ou=verbindungen,ou=system. Sadly I am no expert on LDAP and was not too sure how to optimise it, beyond increasing the cache size attribute of the system partition in server.xml inside ApacheDS. The results were far from promising with average random read times around 50 milliseconds.
In all cases, I optimised my code so that connections to the remote processes were created post EJB construction, and just once, until the EJB instance was destroyed (using the @PostConstruct EJB 3 annotation). In all cases, the average read times were measured per cache entry, based on 1000 random serial cache reads, after reading over 100,000 entries to ensure that the external process had had time to optimised its own in memory key cache.
The results are summarised as follows:
| Solution | Average Read Time |
| MySQL Cache table | 15 ms |
| Cassandra | 1 ms |
| Remote EJB | 2 ms |
| ApacheDS LDAP | 50 ms |
The nice part about using Cassandra would be that we don’t have to write the code for this cache, nor maintain it. Additionally, there are other areas within our landscape that could make good use of a bigtable style solution because the amounts of data are getting very slow to handle, so it would be useful to start getting to know the new world.
The not so nice part about Cassandra, is that it is not standard software at this client. We would need to create a request for architecture and invest time convincing some enterprise architects that we need Cassandra and that our platform people and data centre should invest in order to support it. This could end up involving software evalutations and eventual licence costs if they chose a commercial solution. All this effort could easily cost more than we could possibly save by implementing a single cache in order to reduce the amount of hardware required today. Politics are great, eh 😐 I shall be putting the proposals forward in the new year, let’s see what they bring.
One quick final note: the times measured here are not realistic of the target environment – a laptop doesn’t compare to a cluster! But they can be used as relative indicators to suggest which solutions might be worth further investigation. Only final deployment to production can give the real answer, as shown by this example, although just because Digg had problems, doesn’t mean Cassandra is bad. It does show that you need to think long and hard about your architecture though.
Copyright © 2010 Ant Kutschera