Context – Very Large Software Projects
For this article, I am going to define “very large” as any project involving upward of a hundred people over several years. I’ve had the privilege to work on four such projects in my career, pretty much non-stop since 2007. The latest one is in an organisation that implements SAFe™ with three levels (portfolio, ART and team). I’ve worked as a system architect in an ART since 2017, although normally doing more technical work and sharing the role with a second architect who focuses more on the business side of things (I still love to program and still love hard technical challenges). We currently have two architects per ART, with 75 people per ART and two ARTs working on the company’s number one modernisation project.
Challenges in Communication
A big challenge that we have faced is how to ensure that Product Managers (PMs) and System Architects (SAs) are involved in the analysis and decision making processes, without becoming bottlenecks and reducing the rate of flow within the organisation. Taking a step back, it isn’t just a challenge of keeping those two roles in the loop, rather, keeping all stakeholders in the loop. Examples:
- How can we involve the business stakeholders, so that they can understand the impact of requirements on large software systems, e.g. in order to understand why a project costs what it does?
- How can we make sure that the right people in the organisation are involved in discussions and ultimately decisions?
- How can we ensure that PMs and SAs are involved in exchanges between teams and members of other ARTs, if they should be involved, in order to give input, or get output so that they can maintain an overview?
- How can we involve team members in discussions and analysis, so that they can provide innovative inputs in order to find better solutions?
- Are high level requirements from business owners fully understood or is the essence lost during analysis e.g. due to hand-overs and / or asynchronous interaction? We have had cases where a misunderstanding leads to difficult requirements which were expensive to implement, only to find out later that it wasn’t necessary, as the business wasn’t actually prepared to invest as much as it cost.
While SAFe™ offers several mechanisms and probably most importantly, refinements, we have never really found a good solution for these challenges.
Until this spring, the most efficient solution we had, was to use Wednesday afternoons to run refinements from PMs to the teams (not just product owners, POs). My role involved presenting architectural designs and changes in order to cater for the latest requirements, taking questions and feedback over several weeks in order to optimise the solution, so that it could be efficiently implemented in the next Program Increment (PI, ~12 weeks).
Although this worked well and was a process which we had improved over several years, we found that the PMs and SAs were the bottlenecks and we had hit a physical limit on what we could refine and analyse in a single PI. While the teams never ran out of work, we did find that time and time again, we had very stressful run ups to the PI Planning and sometimes were still running emergency refinements during the planning, instead of the teams being able to actually plan.
When key roles like this become bottlenecks, the organisation tends to compensate and be forced to make assumptions or decisions without the people in these roles being involved. This can work, but when it doesn’t, it can cause two problems. Either the assumptions are wrong or decisions aren’t aligned with the strategy. Or people in those roles cannot continue to do their job well, because they are no longer able to maintain an overview in order to steer the organisation in the correct direction. This is inefficient and causes waste – something we try and reduce in an agile environment. SAs and PMs end up having to fire-fight instead of doing their actual job, which in turn slows the rate of flow in the organisation even more.
Enhancing Communication – The RIPE Framework
Since the spring of 2024 we have been using the RIPE Framework to speed up our flow. It solves the problems mentioned above, by putting the RIght PEople together, at the right time, in order to address problems in a timely manner. It does this by introducing open space technology into the organisational mix, for example by holding a weekly conference day, known as the RIPE Day, in which the most important topics are pitched, planned, discussed in sessions and aligned with all stakeholders during the checkout. It is compatible with frameworks like SAFe™, but has successfully been used in other organisational structures too. It requires no change to teams or their responsibility for software components, which in turn allows existing teams to continue to care for the components they craft. While it might sound expensive to invest up to 20% of the available time in a week, in such an event, we have found that it frees up the calendars of many staff members who were compensating by holding regular weekly meetings anyway. Those, in turn, caused everyone’s calendar to be full, which then meant that not all the right people were able to be in those meetings, which caused the meetings to be inefficient and it blocked decisions from being made, or caused firefighting to be necessary to fix wrong assumptions / decisions later on.
While being introduced to the RIPE Framework, we talked about the term “Shift Left” which is the idea of shifting “resources” (or rather people and their brains) to the left (or perhaps counter-clockwise is better) when viewing a diagram that shows the steps involved in agile development. The term is often associated with DevOps, but can also be applied to the processes which everyone involved in producing software, go through. If a single step becomes blocked, say due to a decision that needs to be made, or a problem that needs to be addressed, the flow reduces. If the right people shift left, i.e. counter-clockwise, i.e. back to that blocked step, to help unblock it, the flow rate can be increased.
Now, bringing the right people together isn’t the complete solution, because it doesn’t necessarily solve the problem of those right people being bottlenecks. The solution we employ (recommendations from the framework) is twofold: i) learning to delegate, for example by using delegation poker and ii) setting boundaries. Both of these tools allow PMs and SAs and indeed other stakeholders to not be a bottleneck, but continue to be able to do their job and have an overview of what is going on.
Delegation poker allows stakeholders to give the required inputs and get the necessary feedback, so that they can continue to align the strategy of an organisation. Boundaries are important for similar reasons…
Setting Boundaries
The following diagram should help to highlight which types of communication and decision making are problematic. It assumes two levels of management above the teams, as mentioned at the start of this article, and that the middle level has a leadership team known as a Troika, consisting of one or more system architects, product managers, an RTE (Release Train Engineer) and perhaps a person responsible for quality assurance. The main problem is that members of the ART troika are not involved in communication, and that makes our job harder, because we cannot maintain an overview of requirements, priorities, architecture, designs, problems in the organisation, conflicts, etc. This leads to the organisation not being able to follow the vision and strategic objectives set by the troika, and having to fire-fight to compensate.
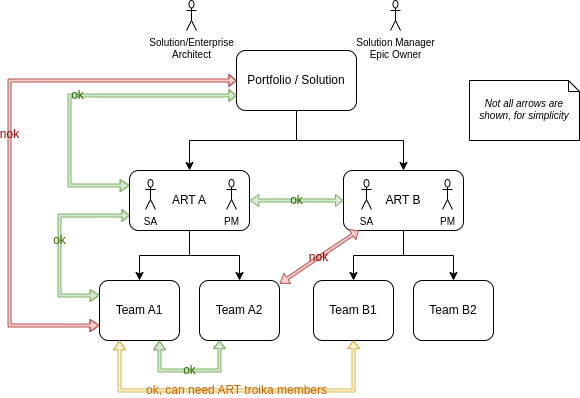
Examples of problematic communications / decisions:
- any from the level(s) above the ART talking directly to teams, can cause conflicting priorities or conflicting (non-)functional requirements. I have seen this happen all too often
- particularly system architects talking directly to teams of other ARTs, bypassing not only the architects who help their teams produce their components, but often bypassing PMs and POs and hence priority. This happens because an architect needs something to be delivered in order for their teams to move forward and is often a result of something that was forgotten during design, or because their requirements are prioritised lower than those of the foreign teams that they are approaching
- contact between teams should be encouraged and nurtured, but is often difficult to achieve, because of the focus that teams have on their own components, or because software engineers can be introverted. It is however important to ensure that assumptions or decisions that they make, are exchanged with the relevant ART troika members, so that they can continue to do their job well. We often talk about giving teams the opportunity to influence architecture, so long as they “return the favour” by involving the relevant SAs and PMs (the word “favour” is used loosely, because why on earth shouldn’t we encourage teams to be involved in architecture and requirements analysis – there are so many advantages of doing this – the ability to scale, finding staff for promotions, shift-left – see above, etc.)
The Result
Using the RIPE Framework, including learning to delegate and setting boundaries so that the right people are continuously talking to each other, has helped us scale. The PMs and SAs are no longer the bottlenecks, but are still able to maintain the overview in order to guide the organisation. We have much less need to fire-fight during PI-Plannings or indeed during PIs. Expensive requirements are more easily corrected before being implemented. Teams are heavily involved in design and analysis and have contact with business stakeholders and users and customers. PMs delegate more to POs and SAs delegate more to “lead devs”, meaning that in theory, we’ve been able to scale our “unblocking power” by a factor of three since we have roughly three teams per SA/PM pair. In the last month we have delivered a major release pretty much on time and I’ve been in the middle of coordinating the last changes and critical bug fixes, and it certainly feels as though we are not only making decisions faster, but also delivering functionality faster. The decisions being made are also more visible to anyone who needs to be able to see them. Our flow is simply beyond impressive and I am very proud to be a part of this organisation and what it is achieving!